

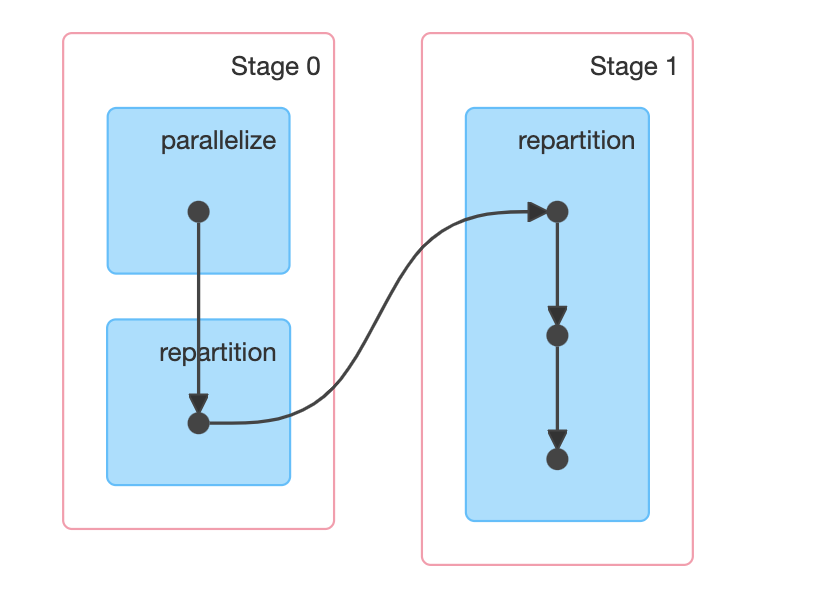
Using different partitioning methods in Spark to help with data skew
Building DataLakes can become complicated when dealing with lots of data. Even more so, when working with heavily skewed data. In this post, we'll be looking at how we can improve your long running Spark jobs caused by skewed data.

Riyaad Kherekar
08 Mar 2023

Automated approach to using AWS SSO for Athena JDBC
Using AWS SSO (IAM Identity Center) to set up CLI and Athena JDBC access for the day

Stephen Hunt
22 Feb 2023

Dynamically Calculating Spark Partitions at Runtime
A brief article covering a method to dynamically calculate the ideal number of Spark partitions at runtime
Stephen Hunt
29 Jun 2022